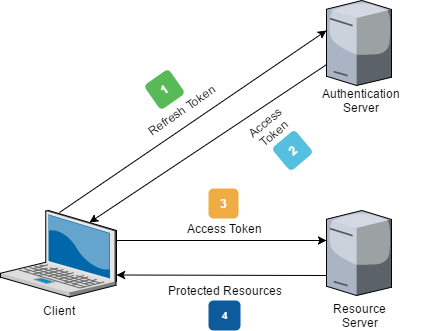
Hace ya unos meses que empezamos en este blog, con una entrada sobre ClosedXML, pero si que es cierto, que se puedo quedar un poco corta, aunque daba las ideas más básicas. Hoy, vamos a ampliar esa pequeña píldora sobre ClosedXML aprendiendo a dar formato a nuestras hojas.
Nuestro objetivo
Vamos a intentar hacer una tabla de colores como la que tenemos a continuación:

Creación del proyecto
Por cambiar un poco desde de la primera parte, vamos a crear un proyecto en .NetCore (ahora que también sabemos instalar el framework en linux o como depurar sobre SSH), para ello, creamos un proyecto de consola:

O desde el CLI de NetCore:
dotnet new console
Lo siguiente que tenemos que hacer es añadir el paquete ClosedXML a través de nuget. Esto se puede hacer a través de la “Consola de Administrador de Paquetes” con el comando:
PM->Install-Package ClosedXML
O también desde el CLI de NetCore:
dotnet add package ClosedXML
Como siempre, utilizando el administrador que integra VS:

Generando y formateando el fichero con ClosedXML
Teniendo claro el objetivo, vamos a ponernos con en faena y analizar el código que hemos utilizado:
using ClosedXML.Excel;
using System.Collections.Generic;
namespace PostClosedXML2
{
class Program
{
/// <summary>
/// Lista de colores para el ejemplo
/// </summary>
/// <returns></returns>
static IEnumerable<XLColor> GetColors()
{
yield return XLColor.Red;
yield return XLColor.Amber;
yield return XLColor.AppleGreen;
yield return XLColor.AtomicTangerine;
yield return XLColor.BallBlue;
yield return XLColor.Bittersweet;
yield return XLColor.CalPolyPomonaGreen;
yield return XLColor.CosmicLatte;
yield return XLColor.DimGray;
yield return XLColor.ZinnwalditeBrown;
}
static void Main(string[] args)
{
using (var workbook = new XLWorkbook())
{
//Generamos la hoja
var worksheet = workbook.Worksheets.Add("FixedBuffer");
//Generamos la cabecera
worksheet.Cell("A1").Value = "Nombre";
worksheet.Cell("B1").Value = "Color";
//-----------Le damos el formato a la cabecera----------------
var rango = worksheet.Range("A1:B1"); //Seleccionamos un rango
rango.Style.Border.SetOutsideBorder(XLBorderStyleValues.Thick); //Generamos las lineas exteriores
rango.Style.Border.SetInsideBorder(XLBorderStyleValues.Medium); //Generamos las lineas interiores
rango.Style.Alignment.Horizontal = XLAlignmentHorizontalValues.Center; //Alineamos horizontalmente
rango.Style.Alignment.Vertical = XLAlignmentVerticalValues.Center; //Alineamos verticalmente
rango.Style.Font.FontSize = 14; //Indicamos el tamaño de la fuente
rango.Style.Fill.BackgroundColor = XLColor.AliceBlue; //Indicamos el color de background
//-----------Genero la tabla de colores-----------
int nRow = 2;
foreach (var color in GetColors())
{
worksheet.Cell(nRow, 1).Value = color.ToString(); //Indicamos el valor en la celda nRow, 1
worksheet.Cell(nRow, 2).Style.Fill.BackgroundColor = color; //Cambiamos el color de background de la celda nRow,2
nRow++;
}
//Aplico los formatos
rango = worksheet.Range(2, 1, nRow-1, 2); //Seleccionamos un rango
rango.Style.Border.SetOutsideBorder(XLBorderStyleValues.Thick); //Generamos las lineas exteriores
rango.Style.Border.SetInsideBorder(XLBorderStyleValues.Medium); //Generamos las lineas interiores
rango.Style.Font.SetFontName("Courier New"); //Utilizo una fuente monoespacio
rango.Style.Alignment.Horizontal = XLAlignmentHorizontalValues.Right; //Alineamos horizontalmente
rango.Style.Alignment.Vertical = XLAlignmentVerticalValues.Center; //Alineamos verticalmente
worksheet.Columns(1, 2).AdjustToContents(); //Ajustamos el ancho de las columnas para que se muestren todos los contenidos
workbook.SaveAs("CellFormating.xlsx"); //Guardamos el fichero
}
}
}
}Lo primero de todo, hemos creado una lista con los colores que queremos utilizar para nuestra tabla. Para ello, utilizamos los colores propios del paquete, que trae una lista enorme de colores:
static IEnumerable<XLColor> GetColors()
{
yield return XLColor.Red;
yield return XLColor.Amber;
yield return XLColor.AppleGreen;
yield return XLColor.AtomicTangerine;
yield return XLColor.BallBlue;
yield return XLColor.Bittersweet;
yield return XLColor.CalPolyPomonaGreen;
yield return XLColor.CosmicLatte;
yield return XLColor.DimGray;
yield return XLColor.ZinnwalditeBrown;
}Una vez que tenemos eso controlado, vamos a entrar al jugo del código. En primero lugar, podemos ver que todo el código esta dentro de un using:
using (var workbook = new XLWorkbook())
{
//Código
}Con esto conseguimos que los recursos utilizados para generar el fichero se liberen correctamente al acabar de usarlos. Lo siguiente que vemos, es como generamos la hoja dentro del libro:
//Generamos la hoja
var worksheet = workbook.Worksheets.Add("FixedBuffer");Una vez que tenemos la hoja creada, añadimos las dos primeras celdas que nos servirán de cabecera para la tabla:
//Generamos la cabecera
worksheet.Cell("A1").Value = "Nombre";
worksheet.Cell("B1").Value = "Color";Vamos a darle formato a la cabecera de la tabla:
//-----------Le damos el formato a la cabecera----------------
var rango = worksheet.Range("A1:B1"); //Seleccionamos un rango
rango.Style.Border.SetOutsideBorder(XLBorderStyleValues.Thick); //Generamos las lineas exteriores
rango.Style.Border.SetInsideBorder(XLBorderStyleValues.Medium); //Generamos las lineas interiores
rango.Style.Alignment.Horizontal = XLAlignmentHorizontalValues.Center; //Alineamos horizontalmente
rango.Style.Alignment.Vertical = XLAlignmentVerticalValues.Center; //Alineamos verticalmente
rango.Style.Font.FontSize = 14; //Indicamos el tamaño de la fuente
rango.Style.Fill.BackgroundColor = XLColor.AliceBlue; //Indicamos el color de backgroundPara trabajar con mayor comodidad, seleccionamos un rango (A1:B1), de modo que todo lo que hagamos sobre el rango, se va a aplicar a todas las celdas del rango, en este caso a A1 y a B1. Lo que hacemos es asignarle los bordes extreriores e interiores, alinear el contenido horizontal y verticalemnte, le modificamos el tamaño de la fuente, y por ultimo, pintamos el color de fondo. Sin ningun problema, generamos la tabla de colores:
//-----------Genero la tabla de colores-----------
int nRow = 2;
foreach (var color in GetColors())
{
worksheet.Cell(nRow, 1).Value = color.ToString(); //Indicamos el valor en la celda nRow, 1
worksheet.Cell(nRow, 2).Style.Fill.BackgroundColor = color; //Cambiamos el color de background de la celda nRow,2
nRow++;
}Como en casos anteriores, asignamos un valor a una celda, y un backcolor a la otra. Con esto, solo nos queda aplicar los formatos y guardar. Vamos a aplicar los formatos:
//Aplico los formatos
rango = worksheet.Range(2, 1, nRow-1, 2); //Seleccionamos un rango
rango.Style.Border.SetOutsideBorder(XLBorderStyleValues.Thick); //Generamos las lineas exteriores
rango.Style.Border.SetInsideBorder(XLBorderStyleValues.Medium); //Generamos las lineas interiores
rango.Style.Font.SetFontName("Courier New"); //Utilizo una fuente monoespacio
rango.Style.Alignment.Horizontal = XLAlignmentHorizontalValues.Right; //Alineamos horizontalmente
rango.Style.Alignment.Vertical = XLAlignmentVerticalValues.Center; //Alineamos verticalmentePero ojo, esta vez, hemos asignado también la fuente:
rango.Style.Font.SetFontName("Courier New");Esto lo hacemos para que la tabla nos quede perfectamente cuadrada al utilizar letras monoespacio. Por ultimo, queremos que las celdas se queden perfectamente a la vista todas, aunque el contenido sea mayor que el ancho de la columna, por lo tanto, vamos a ajustar el ancho de columnas. Eso lo hacemos con:
worksheet.Columns(1, 2).AdjustToContents(); //Ajustamos el ancho de las columnas para que se muestren todos los contenidos
Lo que conseguimos así, es que el ancho de las columnas 1 y 2, se ajuste de modo que se vea el contenido de todas las celdas. Con todo hecho, simplemente guardamos:
workbook.SaveAs("CellFormating.xlsx"); //Guardamos el ficheroY al abrir el excel, veremos que se nos ha quedado una tabla como la que presentábamos al principio. Como siempre, si queréis probar el código fuente, os dejo el enlace al repositorio de GitHub. Esto solo es una pequeña pincelada de todo los que se puede conseguir con ClosedXML y con OpenXML en general. En futuras entradas, seguiremos ampliando su uso.
**La entrada ClosedXML, una manera fácil de dar formato a nuestros .xlsx se publicó primero en Fixed Buffer.**










 Ahí van los enlaces recopilados durante la semana pasada y, como siempre, espero que os resulten interesantes :-)
Ahí van los enlaces recopilados durante la semana pasada y, como siempre, espero que os resulten interesantes :-)


 Desde que apareció Roslyn, C# ha ido evolucionando a pasos agigantados. Tanto es así que es frecuente encontrar desarrolladores que, aunque lo usan a diario, desconocen todo su potencial porque la velocidad de introducción de cambios en el lenguaje es mayor que la de asimilación de novedades por parte de los profesionales que nos dedicamos a esto.
Desde que apareció Roslyn, C# ha ido evolucionando a pasos agigantados. Tanto es así que es frecuente encontrar desarrolladores que, aunque lo usan a diario, desconocen todo su potencial porque la velocidad de introducción de cambios en el lenguaje es mayor que la de asimilación de novedades por parte de los profesionales que nos dedicamos a esto.















 Desde hace una década, el primer post de enero siempre lo reservo para revisar qué publicaciones del blog han sido las más visitadas del año recién finalizado, así que vamos a continuar con esta arraigada tradición una vez más ;)
Desde hace una década, el primer post de enero siempre lo reservo para revisar qué publicaciones del blog han sido las más visitadas del año recién finalizado, así que vamos a continuar con esta arraigada tradición una vez más ;) ¿Cómo? ¿Que a estas alturas no comparo con null de forma totalmente correcta? Pues eso habéis debido pensar muchos al leer este post, el octavo más leído, donde se muestra un escenario en el que
¿Cómo? ¿Que a estas alturas no comparo con null de forma totalmente correcta? Pues eso habéis debido pensar muchos al leer este post, el octavo más leído, donde se muestra un escenario en el que  Ahí van los enlaces recopilados durante la semana pasada. Espero que os resulten interesantes. :-)
Ahí van los enlaces recopilados durante la semana pasada. Espero que os resulten interesantes. :-)