Blogger invitado

Jorge Turrado
Apasionado de la programación, siempre buscando la manera de mejorar el día a día con el desarrollo de tecnologías .NET. Apasionado de este momento tan cambiante y fabuloso para ser desarrollador C#.
Blog: Fixed BufferTras la última colaboración me quedé con ganas de más y, después de que José me haya vuelto a invitar, vengo a hablaros de los paquetes Nuget.
Como desarrollador del ecosistema .NET, seguro que alguna vez has usado el gestor de paquetes NuGet (y si aún no lo has hecho, lo acabarás haciendo antes o después, créeme). Esta herramienta permite empaquetar componentes que cumplen una necesidad determinada, ya sea de terceros o internos de nuestra empresa, dejándolos listos para obtenerlos e incluirlos rápidamente en nuestros proyectos sin tener que compilarlos cada vez o almacenarlos en forma de binarios en una enorme carpeta con cientos de librerías.
Su máximo referente es el repositorio público
Nuget.org, integrado dentro de Visual Studio y repositorio de facto de .NET Core, aunque también existen repositorios NuGet privados, o incluso puedes crear el tuyo sin ningún problema bajándote el paquete
Nuget.Server desde el propio
Nuget.org e implementándolo, ¿es poético verdad? 😊).

Ahora que hemos introducido qué es NuGet para quien no lo supiese, tal vez te hayas preguntado cómo es posible crear un paquete NuGet y publicarlo para que otros desarrolladores puedan utilizarlo. Vamos a ver que es algo realmente sencillo.
Obtener nuestra API key
Lo primero que necesitamos es obtener nuestra API KEY en
Nuget.org, y para ello antes de nada debemos acceder al servicio.
![Login en Nuget.org]()
Hay que tener en cuenta que es necesario utilizar una cuenta Microsoft para poder loguearnos, pero basta que sea una cuenta de Hotmail u Outlook.
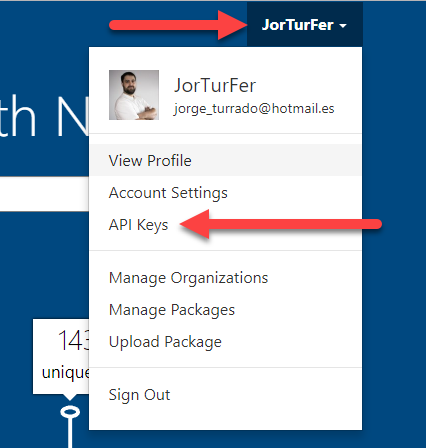
Una vez que nos hemos logueado, pulsamos sobre nuestro nombre para abrir el menú, y vamos a la opción "API Keys":
![Menú API keys en Nuget.org]()
Y tras ello, ampliamos la sección "Create":
![Sección "Create" en Nuget.org]()
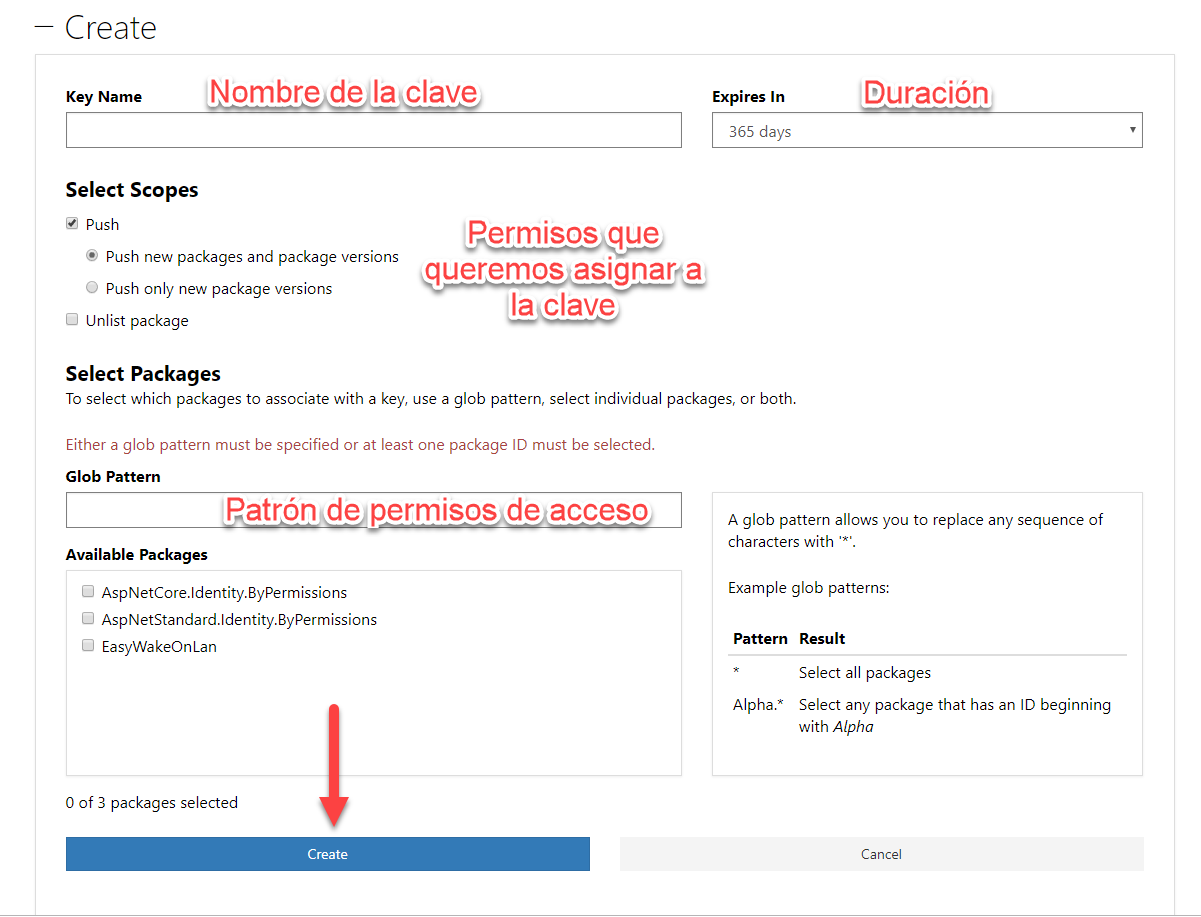
En el formulario que nos aparece es donde vamos a dar los datos para crear la clave:
![Formulario de creación de API key]()
Los datos que nos va a pedir son:
- Nombre de la clave: Aquí vamos a ponerle un nombre que nos permita identificar la clave para gestionarla después.
- Duración: Este es el tiempo de vida de la clave. Una vez pasado ese tiempo, tendremos que renovarla.
- Permisos: Aquí le indicamos si queremos que sólo pueda hacer actualizaciones de paquetes, o crear nuevos paquetes también.
- Patrón de permisos de acceso: Con esto vamos a indicar a qué paquetes queremos que se pueda acceder con esta clave. En caso de que tengamos algún paquete ya creado, también podremos seleccionarlo.
Para nuestro caso, vamos a crearlo con permisos de actualización y poder crear nuevos paquetes, y en el patrón de acceso le vamos a poner un “*” para poder acceder a todos, ya que va a ser
nuestra clave de trabajo como desarrollador. Si lo que estuviésemos haciendo es una clave para
un servicio de CI/CD, lo conveniente sería ajustar los permisos para no permitir control total sobre la cuenta. Después, basta con pulsar sobre el botón “Create”.
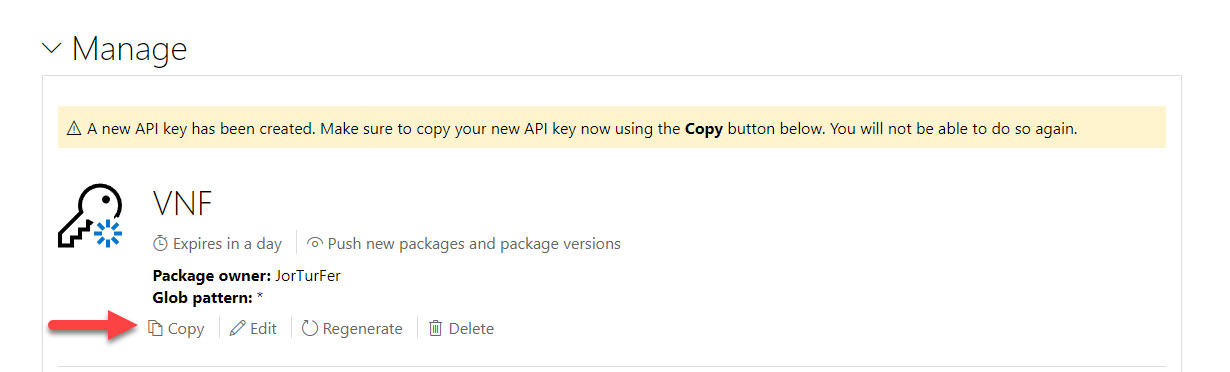
Una vez se pulsemos para crear la clave, nos la mostrará en el apartado “Manage”, dándonos la posibilidad de copiarla. Sólo nos va a dejar copiarla esta vez, por lo que es importante que nos la guardemos en un sitio a salvo, ya que, si la volvemos a necesitar y no la hemos copiado, tendremos que regenerarla.
![Obtener la API key]()
Con esto ya tenemos lo necesario para poder publicar un paquete en Nuget.org, así que sólo nos queda crear el paquete, para lo que vamos a crear un proyecto de librería en Visual Studio. La recomendación es crearla con
.NET Standard en su versión más baja posible, ya que con eso conseguimos que funcione multiplataforma y con la mínima versión del
framework posible, siempre que esa versión incluya todas las APIs que necesitamos.
![Tabla de compatibilidad de .NET Standard]()
Para nuestro ejemplo, vamos a crear una librería .NET Standard 1.0, ya que no vamos a necesitar ninguna API, aunque lo normal es que necesitemos una versión más alta. Para seleccionar la versión de .NET Standard, debemos ir a las propiedades del proyecto de nuestra librería, y seleccionarla en el desplegable.
![Selección de versión de .NET Standard]()
Configurando nuestro proyecto para generar un paquete
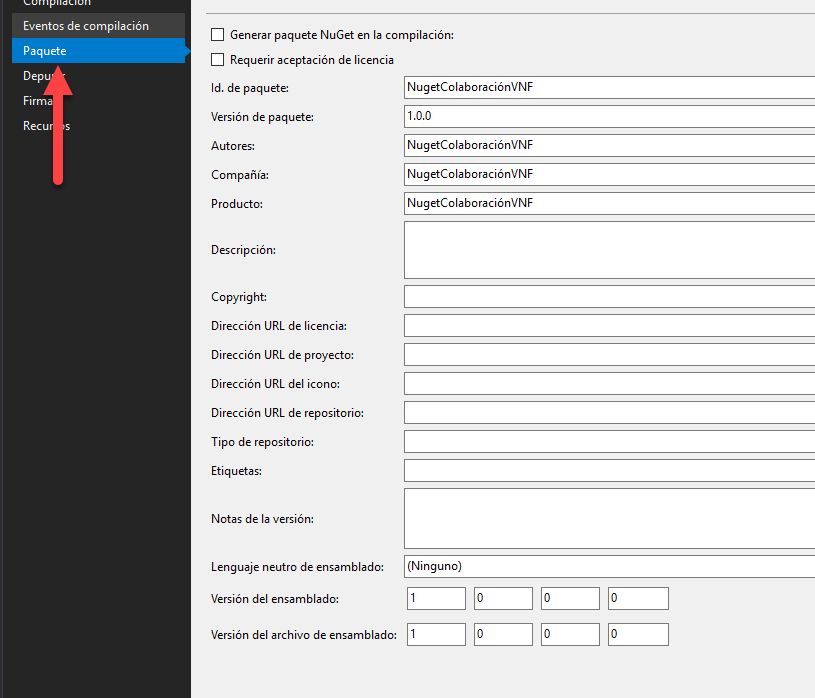
Dentro de las opciones, también vamos a ir a la pestaña “Paquete”, donde le vamos a indicar los datos del paquete.
![Propiedades del paquete]()
Aquí conviene rellenarlo todo, así como darle etiquetas que faciliten buscar el paquete para quien busque algo que resuelva su problema, pero
como mínimo debe tener un “Id. de paquete” único y una versión, ya que es el nombre con el que aparecerá en el repositorio. Una buena idea es buscar en Nuget.org si ya existe un paquete con el nombre que queremos darle, porque si ya existe no podremos subir el nuestro.
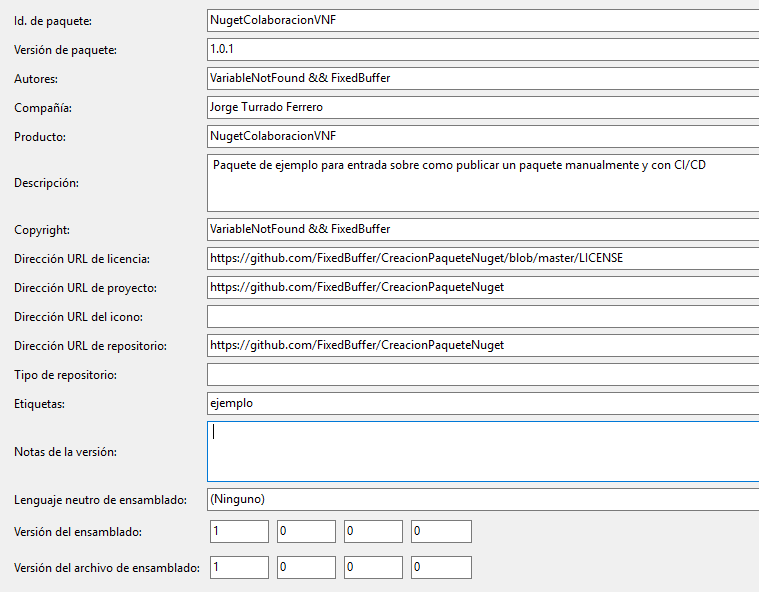
Pese a que esos sean los datos mínimos, es recomendable añadir información adicional sobre el paquete, como el nombre del autor, información de
copyright, una descripción ampliada o las direcciones URL del proyecto, entre muchos otros. La siguiente captura de pantalla muestra el formulario prácticamente relleno en su totalidad para nuestro proyecto de ejemplo:
![Propiedades del paquete totalmente cumplimentadas]()
Una vez tenemos esto listo, basta con que sigamos trabajando en nuestro código de manera normal como lo haríamos en cualquier otro proyecto.
Publicando nuestro paquete en Nuget.org desde línea de comandos
Cuando queremos publicar nuestro paquete, lo primero que vamos a hacer es generarlo, para lo que seleccionaremos la opción “Paquete {nombre de nuestro paquete}” desde el menú “Compilar” de Visual Studio.
![Opciones de Visual Studio para generar el paquete]()
Esto nos va a dejar en la carpeta de salida un archivo “.nupkg” que contiene la librería y todos sus metadatos. Este es el fichero que tendremos que mandar a Nuget.org para que el paquete esté disponible.
![Archivo .nupkg en la carpeta de salida]()
Para poder publicar en Nuget.org, necesitamos tener un cliente Nuget en el equipo, esto se puede conseguir de varias maneras, pero la que nos garantiza poder publicar sin problema, es
instalar el cliente completocomo se indica en la documentación. Una vez que lo tengamos, basta con un sencillo comando:
nuget push Ruta al paquete\YourPackage.nupkg -ApiKey <tu_API_key> -Source https://api.nuget.org/v3/index.json
Donde los dos parámetros que le indicamos:
-ApiKey: Es nuestra clave de acceso al repositorio de paquetes.-Source: Es la URL que nos da el repositorio de paquetes para para enviarle cambios.
En mi caso, como he abierto la PowerShell en la carpeta del paquete, queda algo así:
nuget push NugetColaboracionVNF.1.0.1.nupkg -ApiKey oy2p6bvabu65fjuafebah2oeajh3u5zunjtw6keynpo2uu -Source https://api.nuget.org/v3/index.json
Cuando lo ejecutamos, veremos información en consola indicando que el paquete ha sido enviado correctamente.
![Resultado en consola de un envío correcto]()
Va a pasar un rato hasta que nuestro paquete esté disponible para descargarlo, ya que primero tiene que ser validado por el sistema y luego añadido al índice. Después de este tiempo (nos avisa por email cuando el proceso termina), podemos verlo y descargarlo sin ningún problema.
![Paquete ya publicado en Nuget.org]()
Con esto hemos conseguido crear y publicar nuestro paquete en Nuget.org, de manera que sea posible consumirlo como un paquete más. De todos modos, es cierto que el proceso no es todo lo automatizado que podríamos esperar, y requiere que seamos nosotros quienes nos encargamos de actualizar la versión y subir el paquete cada vez que queramos. En caso de no actualizar la versión y volverlo a subir, nos dará un error diciéndonos que ese paquete ya existe, por ejemplo, si volvemos a lanzar el mismo comando de antes.
![Error en consola indicando que el paquete ya existe]()
Publicando el paquete desde la interfaz web de Nuget.org
Otra opción es utilizar la interfaz web de nuget.org para subir el paquete (con las mismas limitaciones de versiones que hemos comentado y
no es automatizable). Esto puede ser útil si no queremos meternos en la labor de automatizar el proceso (aunque como veremos, es muy sencillo).
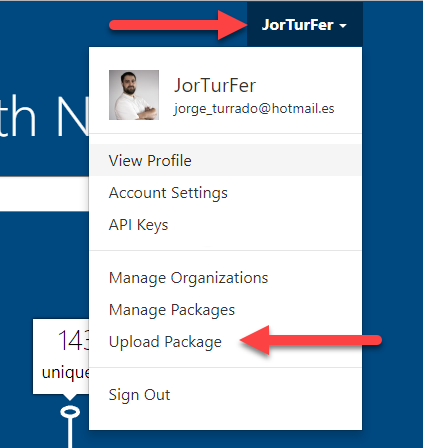
Para utilizar la interfaz web, dentro del menú desplegable, vamos a “Upload Package”:
![Menú para subir paquete a través de la interfaz web]()
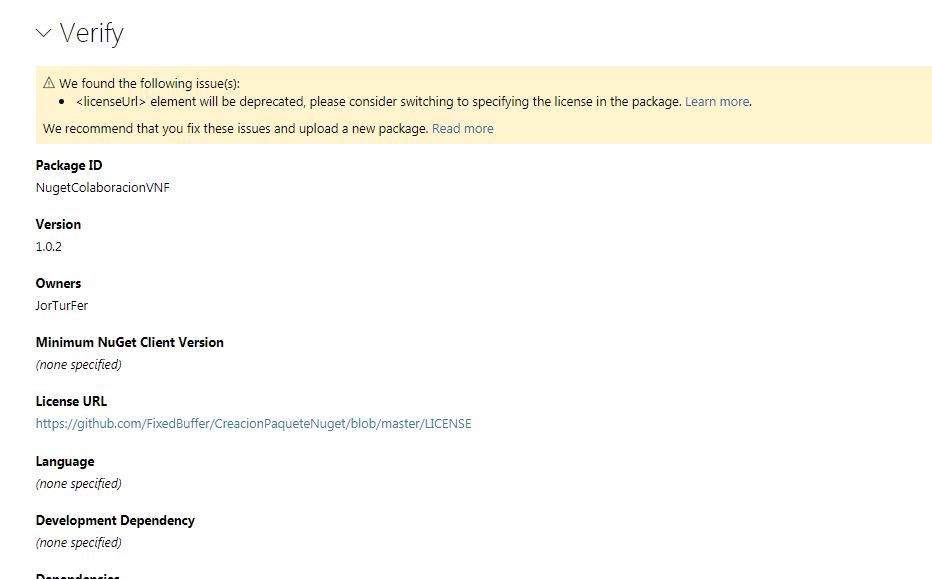
Y dentro del formulario que nos aparece, pulsamos sobre el botón “Browse” para abrir el navegador de archivos y seleccionar el paquete. Una vez seleccionado, se subirá automáticamente, apareciendo tras ello una ventana de verificación con los datos del paquete:
![Pantalla de verificación del paquete]()
Si estamos de acuerdo con todos los metadatos del paquete, simplemente hay que pulsar el botón “Submit” al final de la página.
![Envío definitivo del paquete]()
En cualquier caso, si pensamos que vamos a necesitar actualizar versiones frecuentemente, o simplemente queremos desentendernos de tener que subir los paquetes manualmente, esto se puede solucionar fácilmente utilizando un sistema de despliegue continuo, que sea quien se encargue de identificar la versión y de enviársela al gestor de paquetes.
Si quieres saber cómo puedes hacerlo, facilitándote mucho la vida, como continuación de esta entrada y de mi serie sobre CI/CD, he publicado la entrada:
Además, si nuestro proyecto es abierto, es casi obligatorio habilitar
SourceLink para nuestro paquete (si no sabes que es SourceLink, échale un ojo a
mi entrada hablando sobre ello), de modo que el código fuente se pueda descargar bajo demanda para que quien utilice nuestro paquete pueda depurarlo. De esta forma podrá ver si el error es suyo, y tal vez si el error está en el paquete te proporcionen información relevante para solucionar el problema.
Esto es realmente fácil, basta con que editemos el archivo “.csproj” y añadamos las siguientes líneas al
<PropertyGroup>:
<PublishRepositoryUrl>true</PublishRepositoryUrl>
<RootNamespace>{NombrePaquete}</RootNamespace>
<AssemblyName>{NombrePaquete}</AssemblyName>
Y el siguiente
ItemGroup:
<ItemGroup>
<PackageReference Include="Microsoft.SourceLink.GitHub"
Version="1.0.0-beta-63127-02" PrivateAssets="All" />
</ItemGroup>
Un ejemplo del ".csproj" completo:
<Project Sdk="Microsoft.NET.Sdk">
<PropertyGroup>
<TargetFramework>netstandard1.0</TargetFramework>
<PackageId>NugetColaboracionVNF</PackageId>
<Authors>VariableNotFound && FixedBuffer</Authors>
<Company>Jorge Turrado Ferrero</Company>
<Product>NugetColaboracionVNF</Product>
<AssemblyName>NugetColaboraciónVNF</AssemblyName>
<RootNamespace>NugetColaboraciónVNF</RootNamespace>
<Description>Paquete de ejemplo para entrada sobre como publicar un paquete manualmente y con CI/CD</Description>
<Copyright>VariableNotFound && FixedBuffer</Copyright>
<PackageProjectUrl>https://github.com/FixedBuffer/CreacionPaqueteNuget</PackageProjectUrl>
<PackageLicenseUrl>https://github.com/FixedBuffer/CreacionPaqueteNuget/blob/master/LICENSE</PackageLicenseUrl>
<RepositoryUrl>https://github.com/FixedBuffer/CreacionPaqueteNuget</RepositoryUrl>
<PackageTags>ejemplo</PackageTags>
<AssemblyVersion>1.0.0.0</AssemblyVersion>
<FileVersion>1.0.0.0</FileVersion>
<Version>1.0.1</Version>
<PublishRepositoryUrl>true</PublishRepositoryUrl>
<RootNamespace>NugetColaboracionVNF</RootNamespace>
<AssemblyName>NugetColaboracionVNF</AssemblyName>
<AllowedOutputExtensionsInPackageBuildOutputFolder>$(AllowedOutputExtensionsInPackageBuildOutputFolder);.pdb</AllowedOutputExtensionsInPackageBuildOutputFolder>
</PropertyGroup>
<ItemGroup>
<PackageReference Include="Microsoft.SourceLink.GitHub"
Version="1.0.0-beta-63127-02" PrivateAssets="All" />
</ItemGroup>
</Project>
Con esto me despido, ha sido un placer poder volver a colaborar con Variable Not Found, y como dije la última vez, ¡si me dejan volveré pronto! 😊
José M. Aguilar> Ha sido un placer tener por aquí de nuevo, Jorge. Continuaremos atentos a tu blog, y, por supuesto, esperamos que te animes más veces a publicar en Variable Not Found.
Publicado en
Variable not found.
![]()

 Ahí van los enlaces recopilados durante la semana pasada. Espero que os resulten interesantes. :-)
Ahí van los enlaces recopilados durante la semana pasada. Espero que os resulten interesantes. :-)


 Sin duda, Entity Framework Core es un gran marco de trabajo para implementar el acceso a datos de nuestras aplicaciones, pues es rápido, potente y nos ahorra una gran cantidad de esfuerzo, sobre todo en proyectos muy centrados en datos.
Sin duda, Entity Framework Core es un gran marco de trabajo para implementar el acceso a datos de nuestras aplicaciones, pues es rápido, potente y nos ahorra una gran cantidad de esfuerzo, sobre todo en proyectos muy centrados en datos. 





 Ahora que hemos introducido qué es NuGet para quien no lo supiese, tal vez te hayas preguntado cómo es posible crear un paquete NuGet y publicarlo para que otros desarrolladores puedan utilizarlo. Vamos a ver que es algo realmente sencillo.
Ahora que hemos introducido qué es NuGet para quien no lo supiese, tal vez te hayas preguntado cómo es posible crear un paquete NuGet y publicarlo para que otros desarrolladores puedan utilizarlo. Vamos a ver que es algo realmente sencillo.




































 , etc) y versiones discontinuadas como IronRuby (.NET), MacRuby (Objective-C), y más. Desde ahí podemos acceder a más información sobre el recurso en particular. También encontraremos enlaces a investigaciones, papers, libros, benchmarks y otros recursos.
, etc) y versiones discontinuadas como IronRuby (.NET), MacRuby (Objective-C), y más. Desde ahí podemos acceder a más información sobre el recurso en particular. También encontraremos enlaces a investigaciones, papers, libros, benchmarks y otros recursos.